Neural process 만들기 3
서론
몇가지 시도를 해봤는데 일단 다 실패했다.
어떻게 실패했는지에 대해서 알아보는 시간을 가지자.
문제 상황
일단 문제 상황이 무엇이였는지부터 짚고 넘어가자.
우리가 Neural Process (Gaussian Process)의 형태를 취하면서 바랬던 것은 무엇인가?
네트워크가 ‘이건 내가 이만큼 확신이 있다’ ‘이건 잘 모르겠다’는 것을 말해줄 수 있기를 바랬다.
하지만 정작 학습을 시켜보니까 모든 부분에 대해서 ‘난 이거 완벽하게 확신한다’라고 해버린다.
이건 잘못된 것이다.
시각화!
본격적으로 들어가기 전에, 시각화가 정말로 강력한 도구라는걸 다시 한번 언급하고 넘어가자.
무슨 문제가 있는지, 그걸 순진하게 해결하려고 하면 왜 안되는지를 시각화가 정말로 잘 보여준다.
시각화를 어떻게 했는지를 먼저 설명하고 가자.
두 개의 그래프가 나온다. 하나는 Z의 분포를 보여주는 그래프인데, Scatter이고, 그 자체보다는 축의 범위가 중요하다.
또 하나는 Context값(파란색 점), target 값(주황색 점), 학습된 결과로 나오는 그래프 (여러 색의 그래프)가 있다.
여기에 또 하나 기발한 그래프가 더해지는데, 매우 얇은 붉은 색 그래프이다.
Z값이 (0, 0)일 때부터 (10, 10)일 때까지의 (a, a)점의 모습을 보여주는데, 이 붉은 색 그래프로 Decoder가 Z값을 무시하는지 아니면 Z값을 참조하는지를 쉽게 감을 잡을 수 있다.
기본 코드
일단 저번에 실패한 그 구조를 새로운 시각화와 함께 보자.
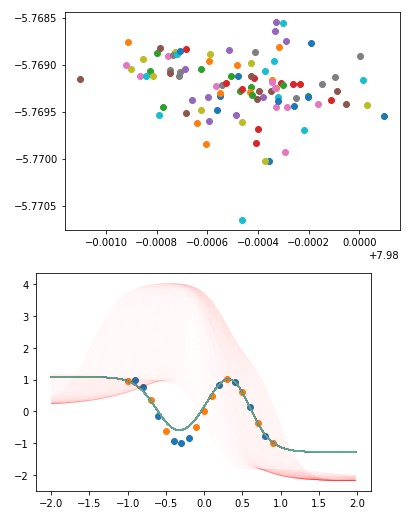
(사실 이 사진은 학습이 정말 잘 된 것이지, 일반적으로 저렇게만 나오진 않는다.)
z encoder로 나온 값들의 표준편차가 매우 작음을 알 수 있다.
그래서 Decoder가 z값을 실제로 참조함에도 불구하고(얇은 붉은색 그래프가 넓게 펼쳐져 있다.) Z값 자체의 차이가 거의 나지 않기 때문에 ‘실패했다’(결과값의 표준편차가 작다)고 할 수 있겠다.
순진한 접근 1 - Restriction
그렇다면 ‘제한’을 두면 어떨까?
그러니까, Z의 표준편차가 작아지는게 문제라면, 그냥 강제로 Z의 표준편차를 키우면 되지 않을까?
Z의 표준편차를 키우려면 그냥 나오는 표준편차값을 역수로 취해서 Loss로 두면 안될까?
어이없어 보이는거 알지만, 진짜로 해봤던 일이다.
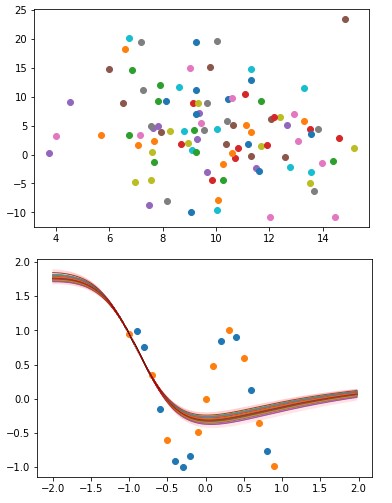
학습 자체도 잘 안됐을 뿐만 아니라, 물론 (잘 안보이지만) 약간의 ‘잘 모르겠어’는 보이지만, 붉은 그래프의 ‘영역’에서 알 수 있듯 그냥 Z값 자체를 거의 무시해버린다.
앞쪽을 전부 잘라먹고 Decoder가 하나의 함수를 학습하기를 원하는 것은 아니니까, 잘못된 것이다.
더 오래 학습해봤자 크게 바뀌는 것도 없다.
순진한 접근 2 - 따로따로
따로따로- 라는게, 저번에 말했다시피 이런 문제가 생기는 이유가 ‘prior와 positerior를 동시에 학습하기 때문’인데
얘내 둘(그러니까 log likelihood항과 kld항)을 따로 학습시키면?
GAN학습하듯이 하나 얼리고 하나 하고 하면 어떨까?
학습 과정에서 일단 Encoder가 전혀 움직이지 않음을 알 수 있다. KL divergence가 초고속으로 0으로 수렴한 후 더 이상 그 쪽을 학습하기를 거부한다.
그래서 Decoder만이 log likelihood 항을 통해 학습되게 되고…
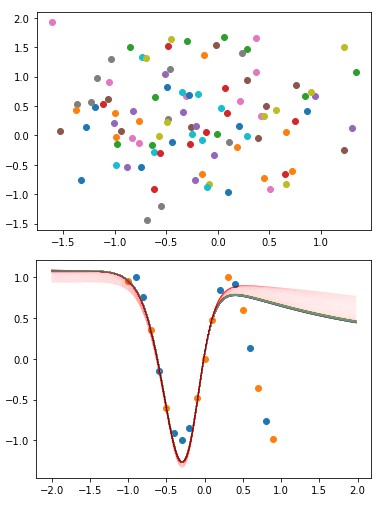
…이런 식이 된다.
다음 시간
…그래서 어떻게하면 내가 원하는대로 잘 되는 것일까. 그건 아직 모르겠다.