Nueral process 만들기 2
서론
저번에 왜 학습이 잘 안됐는지 트러블슈팅에서 시작한다.
문제
이것 저것 해보면서 뭐가 문제인지 알아봤는데-
우연히 생각보다 바보같은 문제가 있다는걸 알아냈다.
대충 설명하면 train test split에서 x와 y를 중간에 바꿔버려서 학습을 x와 y쌍으로 한게 아니라 x끼리 쌍 y끼리 쌍을 시켜버린 것이다(…)
고치고 다시 학습해보자.
문제2
일단 학습은 정말로 잘 된다.
만
내가 보고 있는 글에서도 나타나는 문제가 있다.
엄청나게 빠른 속도로 sigma(불확정성, 표준편차)가 0으로 수렴한다는 것이다.
해당 글 밑바닥에 왜 그런 문제가 나타나는지에 대한 수학적 분석 역시 있다.
대충 시그마 값이 0으로 초고속 수렴하는 것을 막아주는 항이 너무 ‘약하다’고 생각하면 되겠다.
weight의 초기값을 건드려줘서 조금 완화할 수는 있지만, 완화에 불구하고, 학습을 지혹하면 의미가 없어진다.
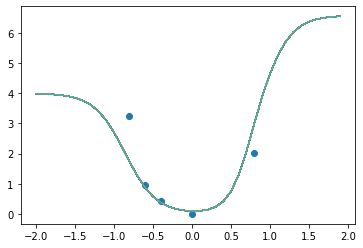
100개의 함수를 샘플링해본 것이다.
모르는 부분은 표준편차(sigma)가 크게 나와야 하는데 (= 여러 개를 샘플링하면 제각각으로 나와야 하는데) 전혀 그렇지 않은 모습을 보여준다.
Gaussian Process를 사용하는 이점이 없다는 것이다.
거기에 애초에 prior과 posterior를 같이 학습시키는 특성 상 (prior를 encoder로 학습시키니까) 그냥 sigma를 엄척 줄여버리면 되는 일이다.
다음 시간
이 문제에 해결책은 없을까? 좀 더 찾아보자.