Optimizer 만들기 9
서론
이제 마지막 두 개, RMSProp과 Adam만 만들면 Optimzer 구현도 어느 정도 끝난다.
RMSProp
RMSProp은 사실 AdaGrad와 큰 차이가 없다. 복붙하고 살짝만 손봐주자.
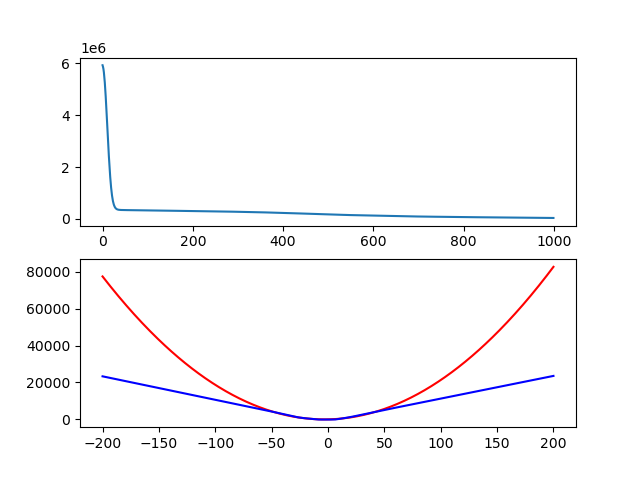
학습률 0.01로 1000 iteration동안 학습시킨 결과다. AdaGrad때와 큰 차이는 없어 보이지만 실제로 약간 더 학습이 많이 진행된 모습이다.
정량적으로 말하면 AdaGrad때에는 loss가 182000 근처였고 (똑같은 lr 0.01, 1000 iteration) 지금은 loss가 36800 근처다.
Adam
사실 다른거 다 건너뛰고 여기로 왔어도 되지만…
아무래도 이게 어떻게 작동하는지 어떻게 코드를 짜야 하는지 익숙해지는데 다른게 도움이 꽤 됐다.
이런 저런 시행착오도 거치고 잘못 짠 부분을 고치고 하는 과정이 꽤 있었다.
뭐, 각설하고 구현하자.
참고로 각종 하이퍼파라미터의 기본값은 PyTorch의 기본값을 이용하고 있다. 아마 논문에 나온 값일거다.
학습률 0.01, 5000 iteration동안 학습시킨 결과를 보자.
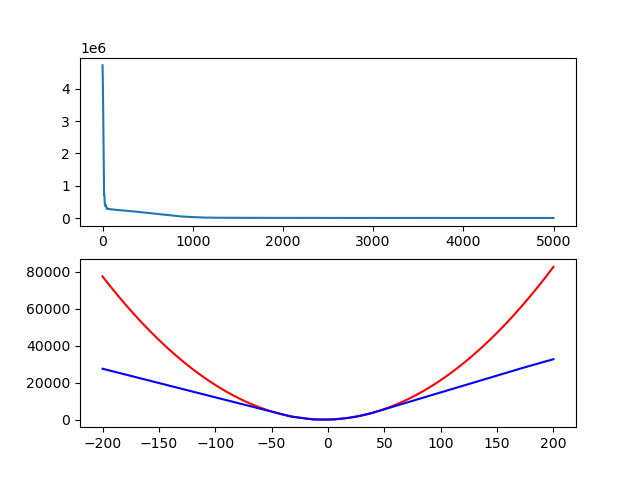
training set의 x가 -50에서 +50까지임을 생각해보면 꽤 괜찮게 나왔다.
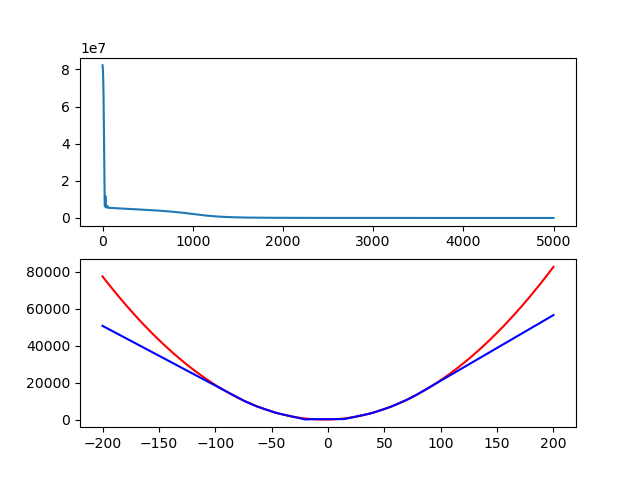
training set의 x를 -100에서 +100까지로 늘려봤다. 괜찮은 결과다.
정리
아무튼 Optimizer들은 다들 구현했다.
이걸 할 수 있을꺼라고는 생각하지 않았는데 생각보다 원리가 단순하다.
(사실 Autograd를 만드는게 더 어렵다. Optimizer 만드는거 절반 정도는 잘못 만든 Autograd를 수정하는 거라고 해도 무방하니까…)
그 다음으로는… Loss들과 layer 등 다른 부분을 채워넣어보자.