Optimizer 만들기 8
서론
뭔가 ground truth하고 다르게 작동하는 것 같았는데…
이것 저것 테스팅하던 도중 뭔가 골때리는 사실을 알아냈다.
일단 다시 한번 Momentum 옵티마이저를 해봤는데, 이게 Ground truth하고 다르게 나오는게 아닌가.
그리고 다시 한번 자세히 보니까, 훨씬 ‘삐죽삐죽’하다.
그래서 그 ‘삐죽삐죽’을 줄이기 위해서 lr을 1/100으로 줄여봤더니… 완전히 똑같은 결과가 나오는게 아닌가.
(여기서 말하는 그래프는 loss의 그래프이다.)
도대체 왜?
Grad의 차이?
대충 보니까 Gradient (미분값) 자체가 100배정도 차이가 나는 모양이다.
어디에서 이 차이가 생길까?
잘못 구현된 평균 backward
지금 평균의 backward는 그냥 전부에게 동등하게 propa를 나눠주고 있는데, 다시 생각해보니까 그러면 안된다.
그냥 전부에게 똑같이 나눠주는건 단순하게 모두를 더했을 때고, 평균을 취할 땐 거기에 나누는 값이 있기 때문에 이를 고려해야 한다.
살짝만 수정해주면 된다.
loss 그래프가 괜찮은 모양으로 나오는 것 같다.
Momentum과 NAG는 다 됐으니 다음으로 넘어가자.
AdaGrad
이번엔 AdaGrad 차례다. 살짝 복잡하게 생겼으니까 조심해서 구현하자.
이걸 구현하면서 알게 된건데, 아직 sqrt를 구현을 안했었다. 구현해주자.
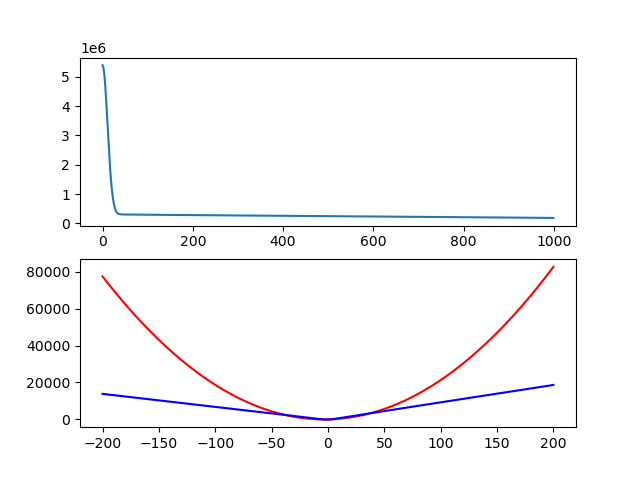
드디어 뭔가가 양쪽 끝이 꺾인 그래프가 나왔다. 행복하다.
다음 시간엔
어디서 잘못된건지 확인하느라 생각보다 시간이 많이 걸렸다.
다음엔 RMSProp하고 Adam을 구현하면 옵티마이저 구현은 끝난다. 그 사이 어딘가 또 잘못한게 아니면.