Optimizer 만들기 5
서론
저번에 ‘다음에 해결할 문제’가 있다고 했었다.
일단 그 문제가 ‘실제로 어떤 것인지’부터 분석해보기로 했다.
문제: 보이는 것
일단은 눈에 ‘보이는’ 문제는…
학습 단계마다 x값 -100~100의 범위에 대해 그래프를 그린다.
실제 그래프, 그리고 학습된 결과 그래프.
그리고 분명히 실제 그래프는 아래쪽 어딘가에 깔려 있는데 ‘학습된 결과 그래프’는 ‘실제 그래프’와는 상관 없는 ‘어딘가’로 수렴하는 모습을 보였다.
문제: 진짜 문제는?
사실 너무…. 뭐랄까, 애매한 면이 있는 문제다.
진짜 문제가 어디에 있는지 어떻게 알아낼 수 있을까?
사실 optimizer 어딘가에 문제가 있을 것 같기는 하지만… 어딘가로 수렴하고 있다는 것도 걸린다.
그래서 생각한게, ‘학습 목표값에 제대로 수렴하고 있는가?’ 하는 의문이다.
‘실제 그래프’와는 한참 떨어지지만… 학습 목표에는 수렴하고 있는게 아닐까?
그리고 둘 중 하나가 어째서인지 잘못된 값을 내고 있는게 아닐까?
그래서 학습 목표인 y값을 scatter plot으로 만들어보았다.
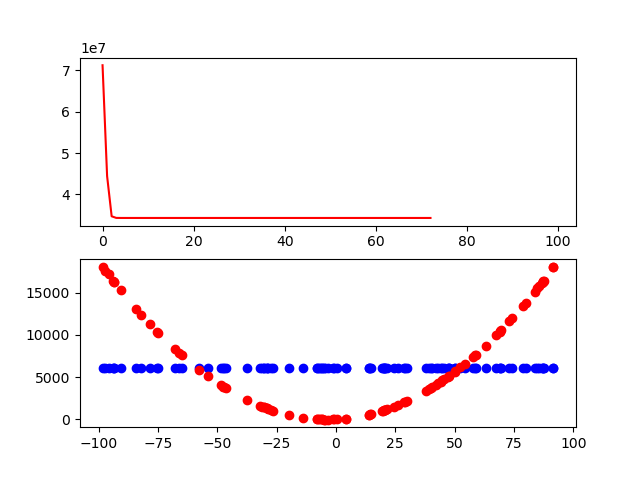
빙고!
사실 학습은 잘 이루어지고 있었다.
또 (x 제곱과 관련 있는 값이니 만큼) y값 역시 제대로 나오고 있다.
문제는 ‘진짜 값’을 잘못 계산하고 있던 것이었다.
…라고 생각했는데, 사실 훨씬 멍청한 곳(!)에 문제가 있었다.
진짜 값도 멀쩡하게 계산했다. 학습도 멀쩡하게 됐다.
그래프를 그릴 때 계산하는 함수에 sigmoid를 하나 빠트린 것이다.
그러니까 그렇게 말도 안되는 값이 나오지.
아직 그래프 형태는 영 그렇지만 이건 sigmoid + sgd를 쓸 때 PyTorch (지금 Ground Truth 혹은 뭐 그 비슷한걸로 두고 있다)에서도 그랬던 것이다.
즉, 일단은 이걸로 오케이인 것이다.
이 쯤에서 한번 끊고, 그 다음으로 넘어가자.
ReLU 구현?
일단 ReLU를 어떻게 구현할지를 생각해봐야 할껀데… 으음… 이게 조금 심상찮다.
ReLU의 구현에는 아마도 np.where이 들어갈꺼다.
라고 생각했는데, 그냥 np.max를 쓰는 것도 괜찮다. 이 편이 구현도 간편할꺼고… 머리 썩이는 일을 좀 덜어줄꺼다.
np.max도 그 나름 문제다. 사실 이걸 어떻게 하면 좋을지 생각을 한 적이 없는데…
ReLU의 미분을 생각하면 생각보다 명확하다.
(왜인지 지금 당장 수식 서비스가 잘 안되는 모양이다… 제대로 입력했을꺼다. 그래도.)
위 식을 보면 알겠지만, max함수에 걸리지 않는 부분은 그냥 0으로 떨궈버리면 된다. 다른 매개변수가 무엇이었든.
정확히는 np.maximum이다. 둘 중에서 더 큰 값을 보내는 함수니까.
기존처럼 FuncClassMaker를 이용한다.
구현은… 조금 까다로울 수 있겠지만, 한번 해보자.
Moment of the Truth
직역하면 ‘진실의 시간’이라고 해야 하나?
무언가 마악 만들고 나서 이게 잘 작동하는지 보는 그런 두려운 시간을 뜻하는 말이다.
두근두근 하면서 돌려봤다.
좋은 소식은, 어디 큰 버그가 나거나 하진 않는다는 것이다.
나쁜 소식은, 그냥 모든게 0이 되어버리기로 결정해버렸다는 것이다.
그냥 x=0 그래프가 되어서 그 상태로 그대로 유지해버린다.
뭐랄까, 묘하다. 첫 두번은 치솟다가, 그 다음에 갑자기 조용해진다…
게다가 ReLU에서 0이 있어서 그런건가 싶어서 LeakyReLU를 만들어서 해보면 아예 nan이 나온다.
어째서…