가우시안 프로세스
서론
가우시안 프로세스라는 말이 이전 Diffusion model을 설명할 때 나왔다.
사실 그게 아니더라도 함수를 확률 분포로 나타내는 것에 대한 해답이 되어줄 수 있겠다.
이미지 하나로 정리
무엇보다 햇갈리던 부분을 이미지 하나로 정리해보고 시작하자.
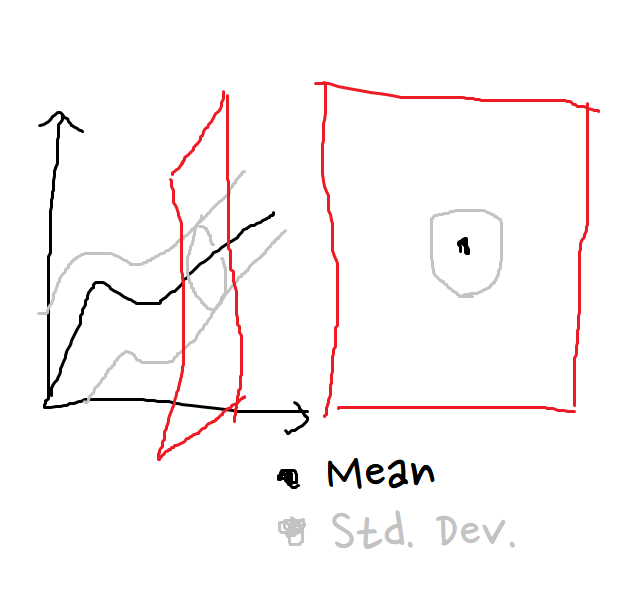
마우스로 그린 역작(?)을 남겨두고, 글을 써보자.
확률 과정
랜덤 프로세스, 확률 과정, 혹은 뭐라고 부르든.
일단 이 것이 무엇인지부터 알고 가자.
확률 분포라는 것은 무엇인가?
대충 머리 속에 감이 오는 것이 있을 것이다. 말 그대로 확률의 분포로, 어떤 시행을 하면 그 시행이 어떤 확률로 얼마나 나올지를 결정하는 무언가…?
아무튼 확률 과정에서는 이 확률 분포가 시간에 따라 달라진다.
저번에 한번 나왔던 마르코프 연쇄도 확률 과정의 일종이다.
자, 그런데 여기서 생각해볼 특이점이 하나 있다.
가우시안 과정으로
꼭 가우시안이 아니더라도- 각 시간의 확률 분포에 일종의 ‘평균’이 있다면, 시간축을 한 축으로 하는 일종의 함수가 되지 않을까?
즉 시간을 정의역으로 하는 함수 말이다.
확률 과정은 그렇다면 시간 -> 확률 분포를 매핑하는 함수가 될 것이다.
여기에 이제 해당 확률 분포가 가우시안 분포 (정규분포)라면 이는 가우시안 과정이다.
위에 올려둔 이미지를 생각해보자.
어떻게 가능하지?
사실 이게 가능한 이유는 간단하다.
실제로 함수를 두 개 만든다. 하나는 평균의 함수고, 하나는 표준 편차의 함수다.
평균의 함수는 우리가 흔히 생각하는 ‘회귀’의 결과물이다.
표준편차의 함수는 이게 얼마나 불확실성이 있는지를 나타내준다.
학습….???
일단 머신 러닝으로는 대충 두 개의 함수를 학습시킨다는 감으로 학습시키면 될 것 같긴 한데
고전적인 방법으로는 이게 조금 많이 어려운 모양이다.
특히 표준편차가.
그래서 ‘표준편차는 이런 함수를 따를 것이다-‘하고 만들어둔 것이 있는데 이를 커널이라고 부른다고 한다.
다음 시간
일단 알아볼건 대충 알아본 것 같고…
Diffusion model을 직접 구현해보자. MNIST 위에서.