Word2Vec
서론
Transformer를 쓰던, 단순한 RNN을 쓰던 필요한 부분이 있다.
신경망에 단어를 단어 그래도 입력할 수는 없기 때문에, 단어를 수치 표현으로 바꾸어준다.
이를 One-Hot Encoding이라고 한다.
One-Hot Encoding은, 예컨데, 10000가지 종류의 단어가 있다면 각 단어를 길이가 10000인 벡터로 치환하는 것이다.
이 때 대부분은 0이고, 딱 한 칸만이 1이 되게 된다.
대충 생각해도 하자가 있을 것 같고 문제들이 넘쳐날 것 같은 그런 느낌이다.
더 좋은 방법은 없을까?
목표
일단 무엇을 만들고 싶은지를 먼저 생각해보자.
일단 One-Hot Encoding된 벡터를 ‘어딘가’에 집어넣어서, 훨신 작은 n차원을 가진 벡터로 바꿔주고 싶다.
이 n차원의 벡터는 One-Hot Encoding과는 다르게 각 차원마다 다들 적당한 값이 들어가 있을 것이다.
또 비슷한 뜻을 가진 단어들끼리는 n차원 공간 상에서 가까운 곳에 위치하고 있으면 좋을 것이다.
조금 더 나아가서, 예컨데 ‘서울 -한국 +일본’같은 연산을 하면 ‘도코’가 나와줬으면 좋겠다.
그러면 각 벡터는 각 단어의 뜻을 제대로 나타낸다고 볼 수 있지 않을까.
구조
Word2Vec의 기본 구조는… 뭐 딱히 설명할 필요도 없이 단순하다.
단순한 행렬 하나이다.
행렬의 차원은 (전체 단어 갯수) x (벡터 행렬 갯수)이다.
One-Hot Encoding을 벡터로 바꾸어주는 단순한 행렬이다.
학습
정말 중요한 부분은 이 곳이다. ‘어떻게 Word2Vec을 학습시킬 것인가?’
기본 컨셉은, 조금 더 고전적인 학습 기법에 기반한다.
즉, 앞뒤의 단어들이 주어졌을 때 가운데 단어가 무엇일지를 유추하는 방법(혹은 그 반대)을 사용한다.
앞뒤의 단어를 가지고 가운데를 유추하는 방식을 CBOW (Continuous Bag Of Words)라고 부르고,
가운데 단어를 가지고 앞뒤 단어를 유추하는 방식을 skip-gram이라고 부른다.
(그 중에서는 스킵그램이 조금 더 좋다고 한다. 어짜피 큰 차이도 없으니까 스킵그램을 중심으로 설명한다.)
구조를 그림으로 그리면 다음과 같다.
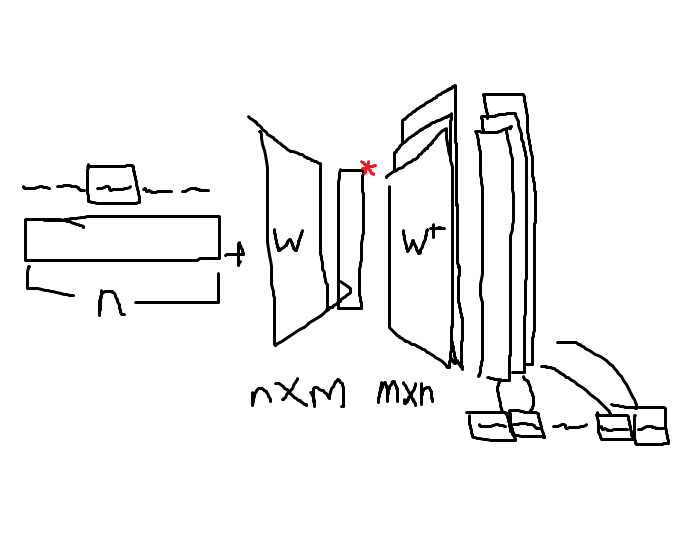
학습시키는 신경망은 두 가지가 된다. W와 W+. 이 둘의 차원은 서로 반대이고 (W: 단어 갯수 x 인코딩 벡터 차원 / W+: 인코딩 벡터 차원 x 단어 갯수) 같은 신경망이 아닌 완전히 따로 학습되는 신경망이다.
주어진 말뭉치에 대해 학습이 완료된 후, W가 임베딩 레이어가 된다. 즉, 위 그림에서 빨간색 *로 표시한 부분이 인코딩 벡터인 것이다.
특징
먼저 임베딩 레이어는 선형 변환이라는 점을 잠깐 짚어두자.
W라는 행렬에는 하나 재미있는 점이 있는데, 이게 사실상 룩업 테이블 역할을 한다는 점이다.
입력이 되는 단어 벡터가 one-hot encoding된 상태이기 때문에 나오는 특징이다.
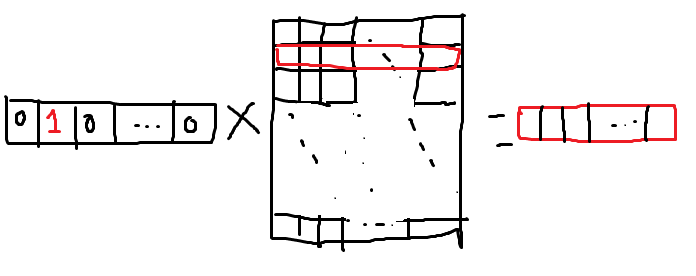
위 그림을 보면 이해가 편할 것이다.
즉 임베딩 레이어는 커다란 dictionary라고 생각하면 편하다.
잡담
Q. 그런데 skip-gram으로 학습했는데 단어의 의미라던가 그런건 어떻게 학습한건가요?
A. 글쎄다?
아마도 어떤 식으로든 단어의 의미를 벡터 내에 함축시켜야지 앞뒤로 어떤 단어가 올 수 있을지 예측할 수 있기 때문이 아닐까 싶다.