Transformer 2
서론
지난 시간에 이어 Transformer에 대해 마저 복습하자.
단순 Attention 메커니즘까지 알아봤었다.
Attention is all you need
‘필요한건 Attention 뿐.’
Transformer를 처음으로 도입한 논문의 제목이다.
저번에 이야기했던 Attention 메커니즘은 RNN을 도와주는 보조적인 역할이었다.
하지만 어떤 머리 큰 사람들이 ‘다 때려치고 Attention만 남기면 개쩌는걸 만들 수 있겠는데?’라는 발상을 해낸다.
그 전에, RNN과 각종 다른 대체 기술들의 단점에 대해 알아보자.
RNN의 단점
RNN의 단점이자, LSTM, GRU, 1D Convolution 등등 다른 모든 시도들이 해결하려고 애썼던 단점이다.
하지만 이들이 모두 공통적으로 가지고 있는 단점이다.
‘망각’. 문장이 길어지면 앞쪽의 내용을 까먹어버린다.
LSTM이나 GRU같은건 (특히 LSTM은 이름부터가 Long-Short Term Memory다.) 어떻게든지 기억의 거리를 늘리는 것에는 성공했지만…
결국엔 망각은 피할 수 없다.
또한 (1D Conv는 해결한 문제지만) 병렬 연산을 하기 힘들다.
하지만 Attention은 망각을 피해간다. 또한 병렬 연산 역시 편리하다.
All attend to all
모두는 모두를 참조한다.
좀 더 괜찮은 설명을 위해 그림판 손그림이 출동할 때인 것 같다.
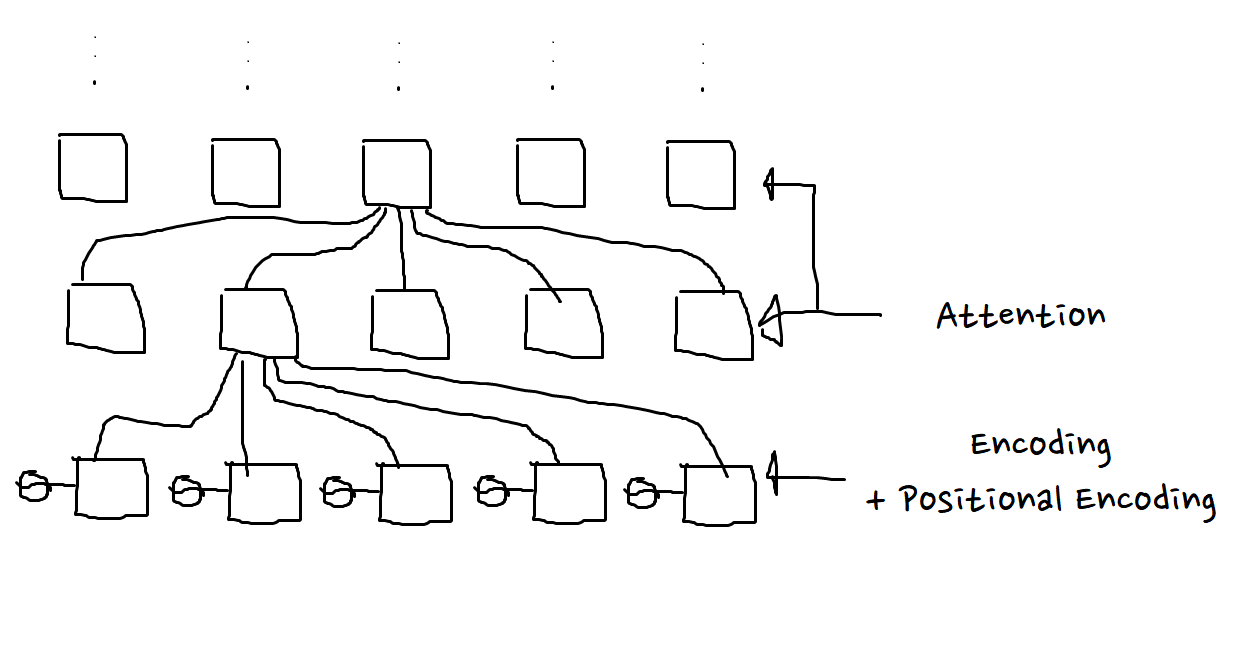
태극무늬는 positinoal encoding으로, 위치 정보를 주기 위한 방법이다.
매 layer마다, 각 위치가 다른 모든 단어와 얼마나 의미상 유사한 점이 있는지를 계산한다.

인터넷에서 퍼온 사진이다. 이런 식으로 각각이 얼마나 연관이 있는지를 계산하는 것이다.
그리고 그 위로도, 위로도… 여러 층을 쌓아올린다.
Key-Query-Value
저번에 ‘다음번에는 Attention이 조금 더 복잡해진다’라고 했었는데, 그 약속을 지킬 때이다.
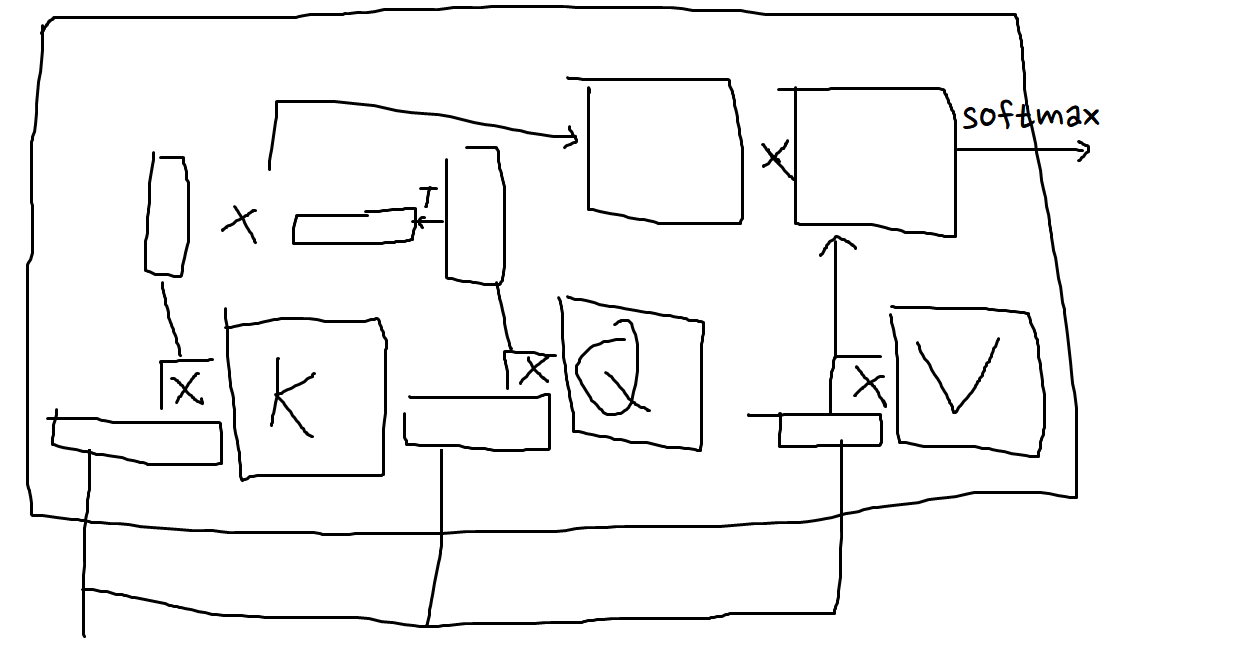
뭔가 많이 있는데, 사실 그닥 복잡하진 않다.
Attention은 ‘어떤 값’과 ‘다른 값’의 유사도를 구하여, 그게 따라 ‘값’의 가중합을 구하는 그런 메커니즘이었는데…
이거를 조금 더 복잡하게 만든 것이다.
‘어떤 값’과 ‘다른 값’, 그리고 ‘값’이 언제나 똑같은 것보다는 살짝씩 차이를 두는 것도 좋지 않을까.
해서 차이를 만들어주는 행렬들을 하나씩 넣은 것이다.
K행렬은 ‘어떤 값’, 즉 Key값이고, 유사도를 구하고 싶은 원본 값의 ‘Key’가 된다.
Q행렬은 ‘다른 값’, 즉 Query값이고, 유사도를 구하고 싶은 대조값의 ‘Query’가 된다.
V행렬은 ‘값’, 즉 Value값이고, 유사도를 구한 후 마지막 벡터가 되어주는 ‘Value’가 된다.
…설명이 조금 이상하긴 한데…
Transformer
뭐 그런 Attention(정확히는 Multi-head버전)들을 가지고 잘 쌓아올려서
Decoder쪽에서 미래(자기 이후 내용)를 참조할 수 없도록 해주는 트릭을 잘 넣어주면
Transformer의 완성이다.

이런 구조다.
말 그대로 어텐션만으로 모든걸 구현한 것이 Transformer의 특징이다.