Transformer
서론
오늘은 Transformer에 대해 복습해보는 시간을 가지자.
배우기는 학교 수업시간에 배웠던 것이다.
Seq2Seq
다른 모든 것에 대해 알아보기 전에, 가장 기초되는 개념부터 알아보자.
Seq2Seq는 자연어 처리의 기초다.
한 문장(Sequence)를 다른 문장(Sequence)로 바꾸는 모델을 Seq2Seq라고 한다. 이름 하나는 엄청 직관적이다.
이러한 Seq2Seq를 어떻게 구현할 것인지가 중요한데…
RNN
먼저 가장 직관(?)적인 접근 방법이다.
Seq2Seq의 가장 큰 문제는 정해진 크기의 Sequence가 입/출력되는 것이 아닌, 그 크기가 유동적이라는 것이다.
그러면 이렇게 해보자.
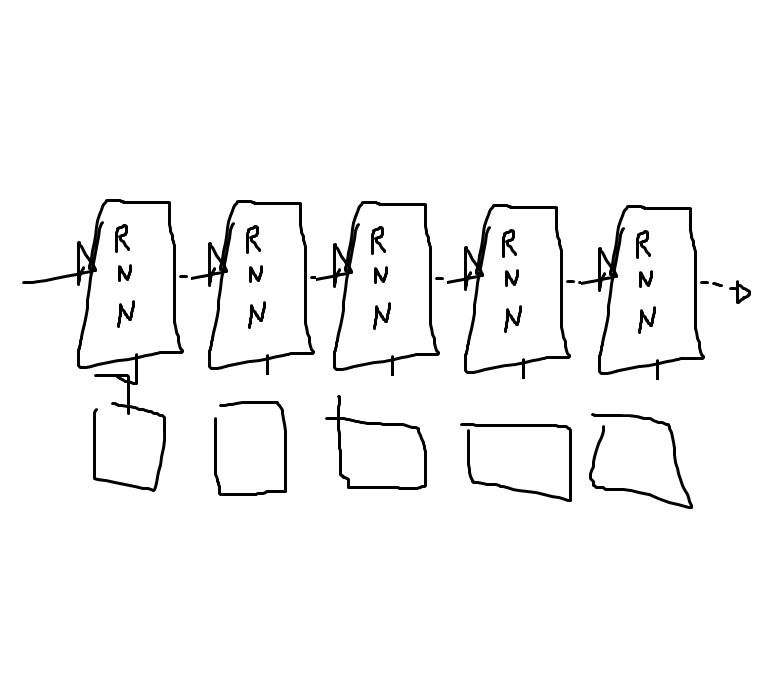
언제나 그렇다시피 저퀄 낙서이다.
다만 복사 붙여넣기는 의도된 것이다.
아래쪽에 있는 삐죽빼죽한 네모들은 단어(의 벡터 - word2vec이라는 또 다른 기술을 이용해서 만들어낸 벡터이다. 이건 또 언젠가 다뤄볼 수 있지 않을까?)들이다.
이게 RNN이라고 되어 있는 부분에 들어간다.
RNN은 입력을 두 개 받는데, 하나는 단어고, 또 하나는 ‘이전 벡터’이다.
(사실 출력도 두가지인데 하나는 생략했다.)
이전 벡터와 단어를 신경망에 집어넣으면 새로운 벡터가 튀어나오는데, 이게 그 다음에 다시 ‘이전 벡터’ 자리에 들어가게 된다.
어떤 의미로는 RNN의 ‘기억’이라고 볼 수 있다.
문제는 RNN이, 실제로 해보니까, 기억력이 형편없다는 것이다.
그래서 사람들은 기억력을 늘리기 위해서 이런 저런 노력을 많이 해봤다.
LSTM이니 GRU니 뭐니 하는, 몇년 전만 해도 ‘최신 기술! ~~ 기술은 쓸모 없다!’ 하는 느낌으로 봤던 것들이다.
그런데 지금은 걔내들이 거의 안보인다.
Attention
이런 노력 중 하나가 ‘집중’이다. 어텐션.
기본적인 아이디어는 이렇다. 책을 읽다가 보면 뒤로 돌아가서 다시 읽고 하는 때가 있지 않는가?
그런 느낌으로, Attention은 Seq를 만들 때 (decoder 부분) 이전 내용을 참조하는 메커니즘이다.
대충 그림으로 표현하면 이렇다.
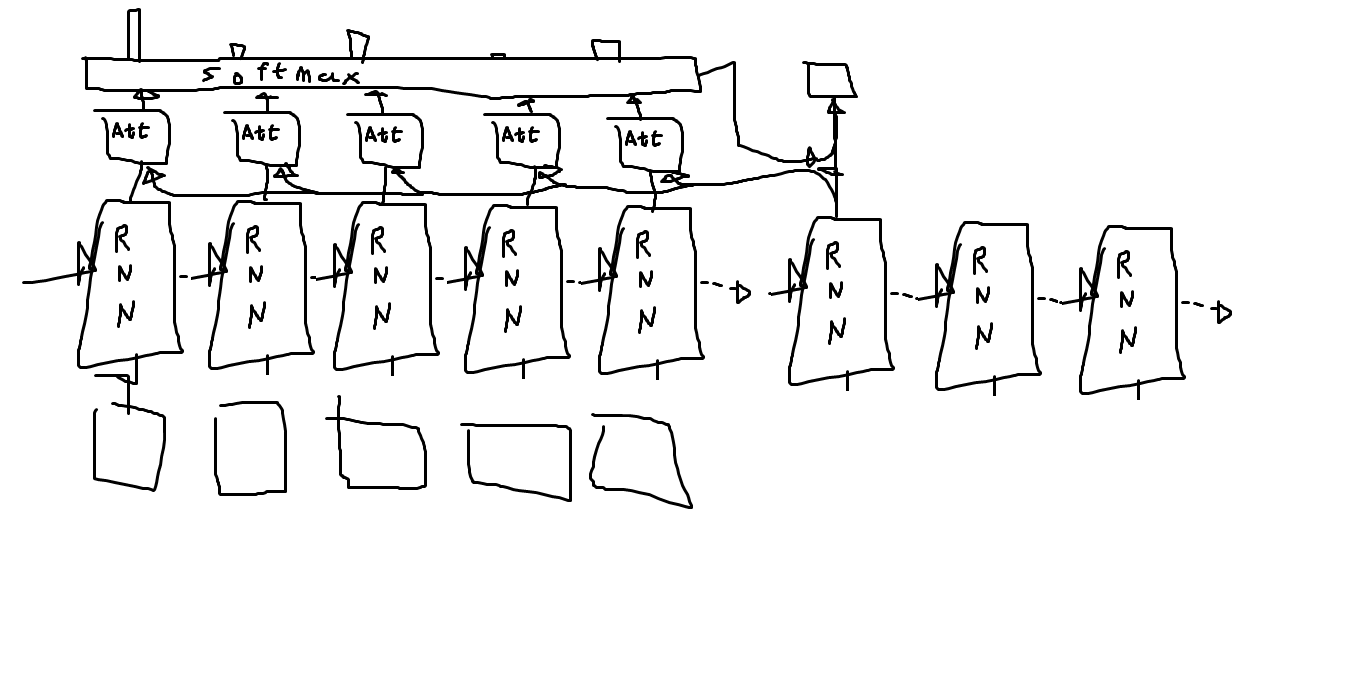
Att라고 쓰인 부분이 어텐션인데, 이 부분은 대충 ‘얼마나 집중할 것인가?’를 계산하는 부분이라고 생각하면 된다.
조금 더 정확한 원리 비스무래한건 다시 알아보자.
아무튼 출력값에 대해 ‘얼마나 집중할 것’인지를 계산하고, 그 계산 결과들을 쫘악 softmax를 취해서 새 문장을 만들때 어느 부분을 참조할지를 정한다.
그 다음에 ‘어느 부분을 참조할지’와 출력값을 인공신경망에다가 때려넣으면 무언가 그럴싸한게 나온다.
이게 Attention 메커니즘의 기본이다.
어텐션 안쪽을 조금 더 자세히 들여다보면 이런 느낌이다.
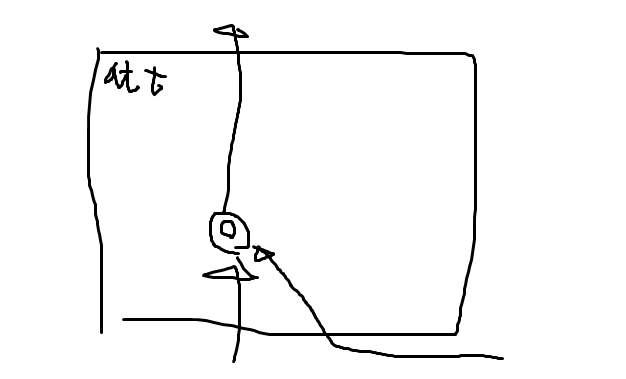
…나도 이게 싱거운거 안다.
(나중에 트랜스포머에 대해 조금 더 자세히 다룰 때는 조금 더 복잡해진다. 믿어도 좋다.)
그냥 단순하게 dot production을 해주는건데,
dot production은 두 벡터가 비슷할수록 큰 값이 나온다. 반면 두 벡터가 차이가 많이 날 수록 값은 작아진다.
그렇기 때문에 유사도를 구하기엔 나름 적합하다. (정 마음에 안들면 여기에 인공신경망을 하나 집어넣어도 된다…만 사실 성능상 차이는 크게 없다고 했던 것 같다.)
이게 어텐션 메커니즘의 기본이다.
다음 시간
이것도 충분히 성능이 좋았는데… 어떤 엄청 똑똑한 양반들이 ‘야 RNN같은거 전부 다 집어치우고 그냥 어텐션만으로 모든걸 구성하면 안되냐?’ 하는 생각을 해냈다.
어텐션을 살짝 고쳐서 그게 가능하게 만들어버렸다.
이를 ‘트랜스포머’(Transformer)라고 부른다.
다음번엔 이거에 대해 더 자세히 알아보자.