Optimizer - 3.옵티마이저: 더 발전
돌아보기
이전 글에서는 Momentum, NAG와 AdaGrad에 대해 알아봤다.
Momentum은 움직이는 방향을 관성으로 쭈욱 움직이는 방식이다.
NAG는 Momentum의 제동력을 높였다.
AdaGrad는 파라미터마다 다른 학습률을 적용시키면서 학습률을 깎아나간다.
AdaGrad는 학습률이 0에 수렴하는 문제가 있었다.
RMSprop
일단 RMSprop라는 이름이 무슨 뜻인지부터 알아보자.
Root Mean Square Propagation, 즉 ‘제곱평균제곱근 전파’의 줄임말이다.
…뭐, 잘 생각해보면 AdaGrad도 제곱 평균을 제곱근해서 사용했던건 똑같았던 것 같다.
그렇다면 AdaGrad와 RMSProp의 차이점은 무엇일까?
AdaGrad의 문제점은 너무 G값(지금까지 얼마나 바뀌어 왔는가?)이 커져서 학습이 전혀 진행되지 않는 상태가 된다는 것이었다.
내가 모르던 개념 중에서 ‘지수이동평균’이라는게 있는 모양이다.
찾아보니까 주식만 잔뜩 나오는데, 대충 ‘최근 항목이 더 큰 의미를 가지게 평균을 내는 방법’인 모양이다.

위키백과에서 긁어왔다.
(아, 이 식의 α와 앞으로 나올 γ는 같은 의미를 가지지만, (1 - γ)가 α다.)
이게 어떤 의미를 가질지를 한번 시각화해봤다. 직접 눈으로 보는게 아무래도 좋을 테니까.
많이 단순화된 Toy example로, G값이 어떻게 변하는지 추이를 알아보고 싶다고 하자.
그라디언트는 계속 평균 1, 표준편차 1의 무작위 값이 나온다고 하자.
AdaGrad는 이 무작위 값을 계속 누적할 것이고, RMSProp은 이에 지수이동평균을 취할 것이다.
결과는 다음과 같이 나온다.
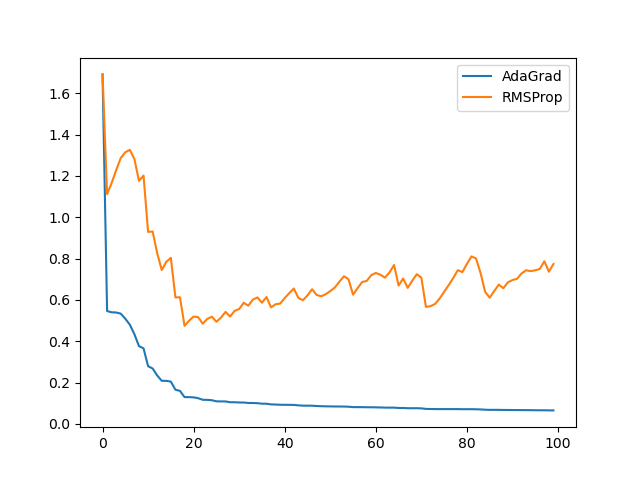
AdaGrad와 RMSProp의 학습률에 붙는 계수 (1 / sqrt(G)값)의 그래프다.
물론 실제와 차이가 나긴 하겠지만, 전체적인 그림은 비슷할 것이다.
적어도 AdaGrad와는 달리 0으로 수렴하지는 않을 것이다.
설명은 대충 됐으리라고 믿고, 공식은 다음과 같다. 사실 AdaGrad와 큰 차이는 없다.
앞에서 말한 것처럼 γ가 조금 붙었다는 것 빼고는 차이점이 없다.
실제로 두 번째 공식은 AdaGrad에서 봤던 그 공식이 그대로다.
- 장점: AdaGrad와 공유한다.
- 장점: 단점은 AdaGrad와 공유하지 않는다.
- 단점: …어떻게 더 좋게 하는 방법은 없을까? 단점이라기 보다는..
Adam
드디어.
원 글에는 AdaDelta에 대한 이야기도 나와 있지만, 내 개인적인 목표는 Adam을 이해하는 것이었기 때문에 바로 Adam으로 넘어간다.
Adam은 RMSProp와 Momentum을 합친 방식이다.
노트: 인터넷을 조금 더 뒤져본 결과, Momentum을 그대로 합쳤다고 보기는 어려울 것 같다.
다시 복습해보자. Momentum은 현재 이동하는 방향에 관성을 주는 V를 추가로 사용한다.
물리적으로 생각하면 운동량에 관성이 적용된다고 생각할 수 있다.
한편 RMSProp은 현재 이동하는 방향 제곱에 관성을 주는 G를 추가로 사용한다.
물리적으로 생각하면… 으음, 운동 에너지에 관성이 적용된다고 해야 하나?
물리를 공부한지 좀 오래되기도 했지만 뭔가 말이 안되는 것 같은 기분은 들지만…
그냥 가속도/2차 가속도 같은 기분으로 생각해보자.
이제 이 둘을 합칠 것이다. Momentum 부분이 어느 부분이고, RMSProp은 어느 부분인지, 또 Momentum이 어떻게 바뀌었는지를 한번 잘 살펴보자.
- 가장 자주 사용됨
총정리
GD, 미니 배치 SGD, Momentum, NAG, AdaGrad, RMSProp, Adam에 대해 알아보았다.
각종 Optimizer들에 대해서 제대로 공부한건 이번이 처음이었던 것 같다.