Optimier - 2.옵티마이저: GD/SGD
돌아보기
이전 글에서는 그라디언트에 대한 내용을 정리했다.
그라디언트란 편미분의 열벡터로, 그래프가 기울어진 크기와 방향을 나타낸다.
그라디언트의 방향으로 ‘움직인다’면 함수의 값이 커진다.
그라디언트의 기호는 ∇이다.
최솟값과 극솟값
다른 내용으로 넘어가기 전에, 최솟값과 극솟값에 대한 이야기를 해보자.
다음 그래프를 보자.
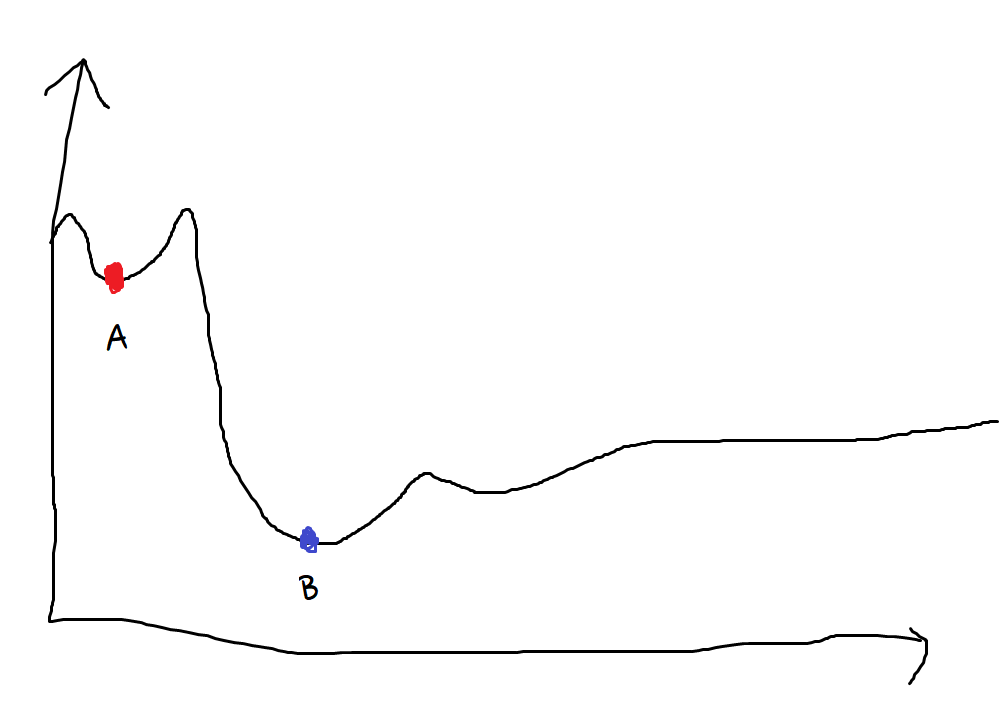
대충 마우스 손그림으로 그린 그래프다.
A지점처럼 주위보다 낮은 지점을 극솟값이라고 부른다.
혹은 local minimum라는 표현을 더 자주 사용하게 될 것이다.
B지점처럼 가장 낮은 지점을 최솟값이라고 부른다.
영어로는 global minimum이라는 표현을 쓴다.
최적화를 ‘구슬을 굴리는 것’이라고 생각해보자.
우리는 구슬이 가장 낮은 곳, 최솟값 위치에 떨어지기를 바랄 것이다.
하지만 구슬은 어디에 놓느냐에 따라 각기 다른 곳에 도달할 것이다.
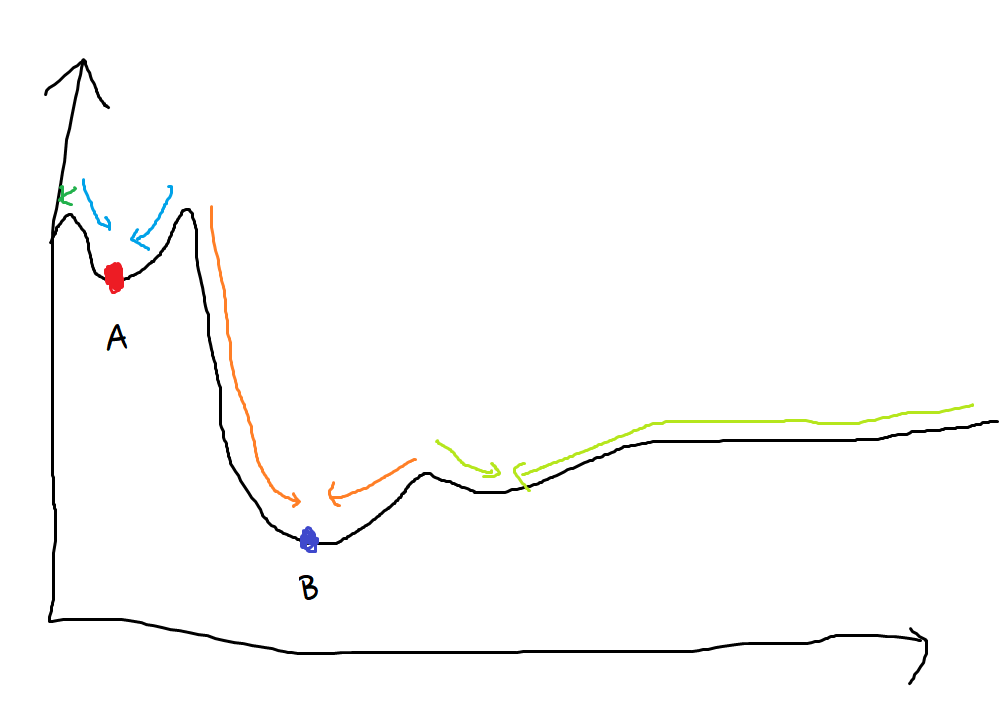
이런 저런 방법을 사용해서 극솟값에서 벗어나 최솟값으로 향하게 시도해볼 수는 있지만…
구슬이 ‘최솟값’에 떨어지게 만드는 방법은 없다. 오직 극솟값에 도달할 뿐이다.
극솟값을 향하게 만들 수 있을 뿐이다.
그나마 위 그림같은 2차원이라면 대충 시도를 많이 해 보면 최솟값에 도달할 수야 있겠지만
우리가 다룰 차원은 무지막지하다. 수천만 차원에 이를 수도 있다.
타협
한 가지 다행인 것은, 차원이 많을 수록 극솟값에 머무를 확률이 낮다.
…다른 한 편으로는 국소 최적점에 고착되려면 차원의 모든 축에서 고착되어야 하기 때문에 3차원보다는 다차원에서 고착되기가 더 어렵다.
‘마스터 알고리즘’, 페드로 도밍고스 190p.
하지만 반대로 극솟값의 갯수도 그만큼이나 많아진다.
한편으로는 공간의 차원이 더 높을수록 표면이 더 복잡하고 국소 최적점이 더 많을 가능성이 높다.
‘마스터 알고리즘’, 페드로 도밍고스 190p.
즉 안 좋은 소식 하나, 좋은 소식 하나다.
안 좋은 소식은 최솟값을 사실상 기대할 수 없다는 것이다. 분명 어딘가에 최솟값이 있기야 하겠지만…
좋은 소식은 최솟값 대신 얻은 극솟값도 나름 괜찮을 것이라는 것이다.

최솟값과 극솟값에 대한 제약사항을 알아봤으니, 이제 본격적으로 Optimizer에 대해 알아보자.
Gradient Descent
경사 하강법, Gradient Descent는 가장 기본적인 Optimizer다.
먼저 수식을 보도록 하자.
사이트마다 수식이 다르기 때문에 그냥 내가 알아서 만들기로 했다.
뭔가 수학적으로 잘못되거나 그럴 수도 있긴 한데, 그냥 그런가보다 하자.
W는 Weight, 즉 가중치이다. 지금까지 말한 매개변수이며, 우리가 최적화하고자 하는 대상이다.
α는 학습률, 즉 얼마나 빠르게 학습할 것인지를 나타내는 수치이다.
학습률이 너무 작으면 학습이 지나치게 느려지고, 학습률이 너무 크면 최적인 지점을 벗어나거나 심하면 수렴하지 않을 수도 있다.
적당한 값을 설정해 주는 것이 중요하다.
Loss는 ‘현재 얼마나 오차가 나는지’를 알려주는 함수이다.
우리의 최종 목표는 Loss를 0에 가깝게 낮추는 것이다. 따라서 Loss의 그라디언트를 사용한다.
F(X; W)는 W라는 가중치를 가진 모델 F에 입력 X를 넣으라는 뜻이다. 아마도 이렇게 쓰는 것이 맞을 것이다.
여기서 X는 학습 데이터 전체이다.
즉, 학습 데이터 전체에 대해 Loss를 계산하고, 그 Loss 함수의 Gradient를 계산한 후, 그 Gradient가 가르키는 방향으로 움직인다는 뜻이다.
- 단점: 느리다. 엄청.
- 단점: Local Minima에 빠질 확률이 제일 크다.
Stochastic Gradient Descent
용어가 살짝 햇갈리는 부분인데, Mini-Batch Stochastic Gradient Descent라고 표현하는게 조금 더 엄밀한 모양이다.
기본 식은 거의 똑같다. 하지만 없던 Σ가 보이고, (i) 첨자가 보인다. 무슨 뜻일까?
SGD는 미니 배치(Mini-Batch)를 이용한다.
미니 배치란 데이터를 여러 개 (N개)로 쪼갠 것이다.
즉 데이터를 쪼개서, 각각의 데이터에 대해 그라디언트를 구한 후, 그 그라디언트를 평균낸 방향으로 움직인다는 뜻이다.
이름의 Stochastic은 ‘확률론적인’이라는 뜻이다. 뭔가가 혼란스럽고 결정적이지 않은 그런 느낌이다.
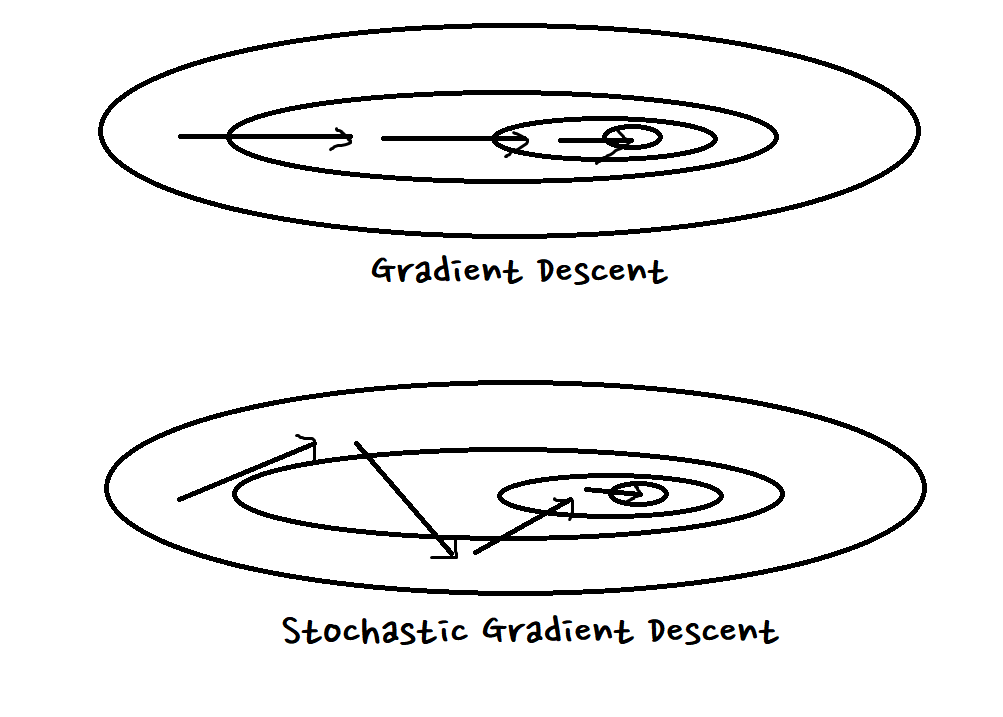
Gradient Descent와 Stochastic Gradient Descent의 차이는 대충 이렇게 생각하면 된다.
- 장점: GD보다 빠르다.
- 장점: GD보다 Local Minima에 빠질 확률이 낮다.
꽤 혼란스럽게 걸으며 가기 때문에 얕은 Local minimum에 빠졌을 때엔 빠져나올 수 있다.
- 단점: 그래도 느리다.
이후?
여기까지는 정말로 간단하다.
대학교 학부 과정에서도 이 정도는 가르치기도 하고, 그 정도로 나름 중요한 내용이기도 하다.
하지만 실제로는 GD나 SGD는 느리기도 하고 해서 잘 사용되지 않는다.
인터넷 찾아서 아무 인공 신경망 코드를 열어보면 보통 Optimizer는 Adam같은걸 사용할 것이다.
어떻게 발전해 나갔는지에 대해서는 다음에 알아보자.